Sometimes you need to loop over a big pile of stuff and execute an action for each item. In the Wikibase software, this for instance occurs when we want to rebuild or refresh a part of our secondary persistence, or when we want to create an export of sorts.
Historically we’ve created CLI scrips that build and executed calls to the database to get the data. As we’ve been paying more attention to separating concerns, such scripts have evolved into fetching the data via some persistence service. That avoids binding to a specific implementation to some extend. However, it still leads to the script knowing about the particular persistence service. In other words, it might not know the database layout, or that MySQL is used, it still things via the signature of the interface. And it’s entirely possible you want to use the code with a different source of the thing being iterated over that is in a format which the persistence interface is not suitable for.
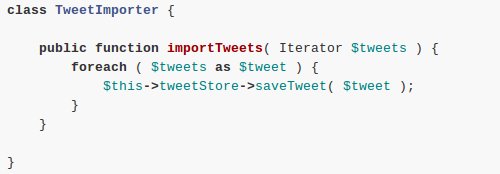
All the code doing the iteration and invocation of the task needs to know is that there is a collection of a particular type it can loop over. This is what the Iterator interface is for. If you have the iteration code use an Iterator, you can implement and test most of your code without having the fetching part in place. You can simply feed in an ArrayIterator. This also demonstrates the script no longer knows if the data is already there or if (part of it) still needs to be retrieved.
When iterating over a big or expensive to retrieve set of data, one often wants to apply batching. Having to create an iterator every time is annoying though, and putting the iteration logic together with the actual retrieval code is not very nice. After having done this a few times, I realized that part could be abstracted out, and created a tiny new library: BatchingIterator. You can read how to use it.
5 thoughts on “Some fun with iterators”